 Firefly
Firefly Microservices in Data Engineering

介绍
在阅读了Daniel Beach的一篇关于在数据工程领域使用微服务的机会的文章(https://dataengineeringcentral.substack.com/p/microservices-for-data-engineering)后,我受到启发,分享我在这方面的经验。
去年,我用Golang开发了自己的Kafka Connect实现,以从许多主题中摄取数据。让我们看看是如何做到的。
先前解决方案的问题
技术栈是Azure Eventhub作为消息系统,Kubernetes和Databricks。后端团队有数百个通过Eventhub进行通信的微服务。数据工程团队需要从其中许多微服务中摄取数据。现有的解决方案是使用Eventhub Capture服务,只需几次点击,就可以配置从Eventhub队列到数据湖的数据摄取,并以Avro格式定期存储。
该解决方案运行良好,但成本高昂,整个公司Eventhub成本的一半是由于捕获服务造成的。而我们甚至还没有开始从吞吐量最高的队列(每天300 GB)中捕获事件。
项目需求
新的解决方案应该是:
- 更便宜
- 高效
- 标准化且可复制,适用于尽可能多的主题
- 易于部署和配置
- 易于维护
我提出的解决方案是用Golang开发两个模块。一个用于管理Consumer配置和高级逻辑,另一个用于实现数据摄取逻辑(如将消息批量写入文件,然后确认消息)。然后,我会为每个Eventhub主题部署一个微服务。在每个微服务中,唯一的代码就是导入数据摄取模块并调用摄取启动函数。其余的都是包含Kubernetes、Eventhub、secrets等配置的Yaml文件。因此,要创建和部署一个新的微服务,我只需复制现有的一个,在VS Code中用简单的替换更改配置变量的名称,并在需要时更新Kubernetes的RAM和CPU值。就是这样,在5分钟内我就可以准备好部署它。
微服务创建的文件格式是包含多行json的Txt。原因是没有使用schema registry。因此,无法管理模式演化,我们会丢失新字段。将其与schema registry和parquet文件格式一起使用,并检查性能,这将是很有趣的。
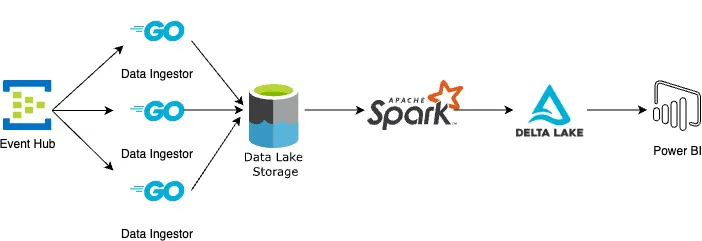
正如我们从架构中可以看到,微服务的作用仅仅是原始数据的纯粹摄取,没有其他功能。这个解决方案使我们的团队能够从Eventhub大规模地持续摄取数据,并在ETL执行频率方面给了我们很大的灵活性。我们每分钟都有数据落地到Azure存储,然后我们使用Databricks的Autoloader对其进行增量加载、转换并准备在Power BI中报告。我们可以近乎实时地运行Databricks管道,或者每天运行一次,根据我们的需要而定。但是成本要低得多,否则我们即使不需要,也不得不使用Eventhub capture或Spark streaming。
然后,我们开始从接收来自API网关的所有消息的主题中摄取数据,每天300 GB。微服务甚至没有畏缩,它们工作得非常出色。即使其他从未使用过Golang的团队成员也能在几分钟内创建和部署它们。
为什么选择Golang?
数据工程团队的大多数人主要擅长使用Python。然而对于这种类型的项目,我认为一种专门为后端和高吞吐量工作负载设计的静态类型语言会是更好的选择。
后端团队的大多数微服务都是用Java和Golang编写的,所以我决定使用Go。在几周内,我学习了该语言的基础知识,并开始在业余时间尝试这些想法。使用Go而不是Python的另一个优势是,后端团队已经有许多DevOps管道用于测试、检查、构件、部署等(而Python没有)。此外,如果我们遇到紧急情况,公司内部会有必要的技能组合。
Share
If this article helped you, please share it with others!
Some content may be outdated