 Firefly
Firefly 数据库扩展的五大技术

应用程序最初并不是为了处理高流量而设计的。这就是为什么随着用户基数的增长,系统会经历显著的瓶颈。
最常见的瓶颈罪魁祸首是数据库。
在扩展系统时,专注于数据库的解决方案往往是最容易采取的措施。
在我们深入探讨扩展数据库的最佳选项之前,重要的是要注意,系统不应该过早地进行优化。这是因为扩展解决方案往往会引入以下复杂性:
- 系统变得更加复杂,涉及更多的部分和变量。
- 添加新功能所需的时间变长,因为需要考虑更多的组件。
- 随着需要适应更多边缘情况,代码可能更难测试。
- 发现和解决错误变得更加复杂。
为了交付一个性能合理的系统,以下五种数据库扩展技术值得考虑。
缓存数据库查询
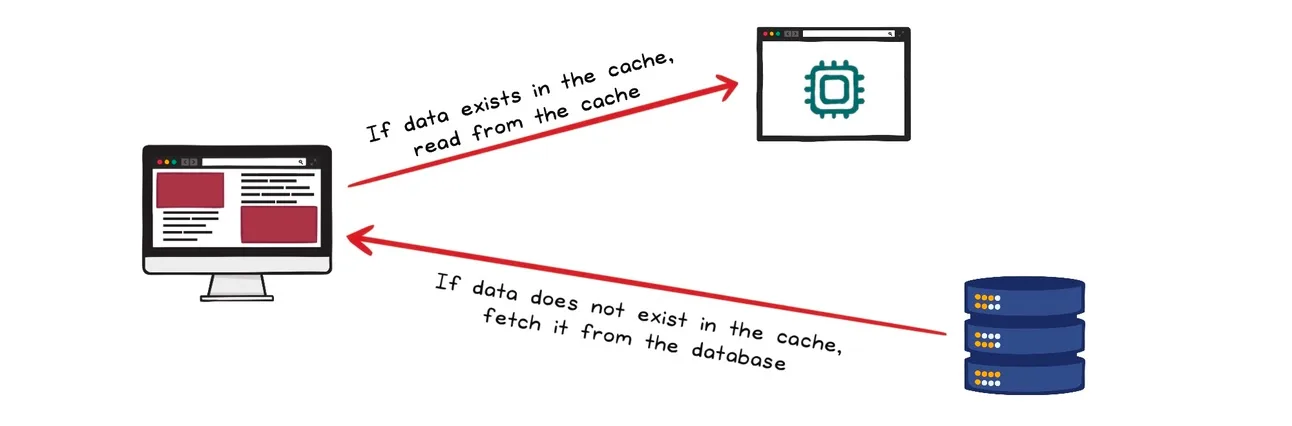
缓存数据库查询是你可以对数据库负载进行的最简单的改进之一。通常,一个应用程序会有少数几个查询构成了请求的大多数。
与其每次都通过网络往返获取数据,不如简单地在网络服务器上的内存中缓存它。
第一个请求将从数据库获取数据并在服务器上缓存结果,未来的请求只需从缓存中读取。这样可以提高性能,因为数据在网络中的传输时间减少了,而且更接近客户端。
数据库索引
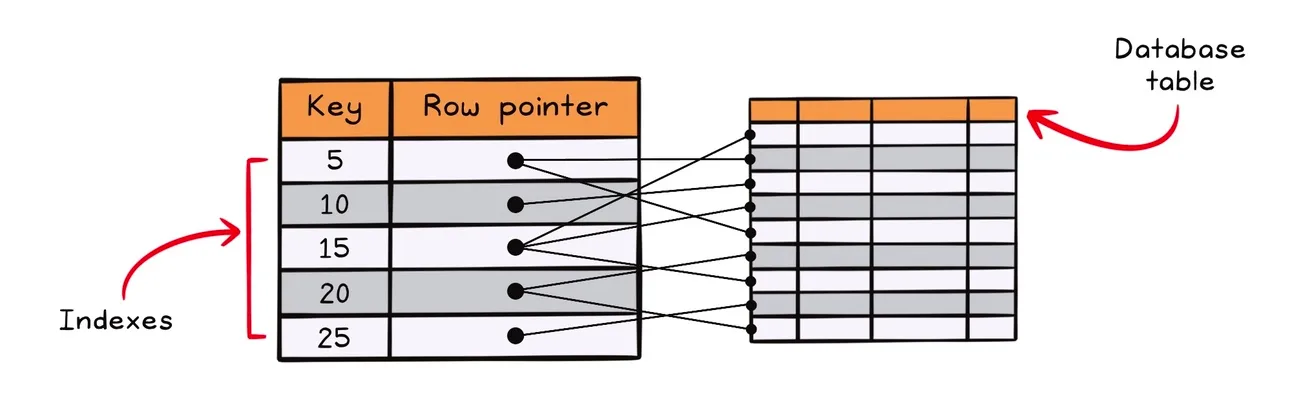
数据库索引是一种提高数据库表数据检索操作速度的技术。索引用于快速定位数据,而无需每次访问表时都搜索表中的每一行。
根据表中的行数,这可以为使用索引列的查询节省大量时间。
移动会话数据
许多应用程序在 cookie 中保存会话 ID,实际的会话数据则保存在数据库表中。这给数据库带来了很大的负载。一种替代方案是将会话数据转移到像 Redis 或 Memcached 这样的内存缓存中。虽然这提高了访问速度,但如果缓存宕机,数据可能会丢失。另一种方法是使用 JWT,它允许你直接在 cookie 中存储会话详情,减少了服务器端会话的依赖,但它也有自己的一套问题。
数据库读取复制
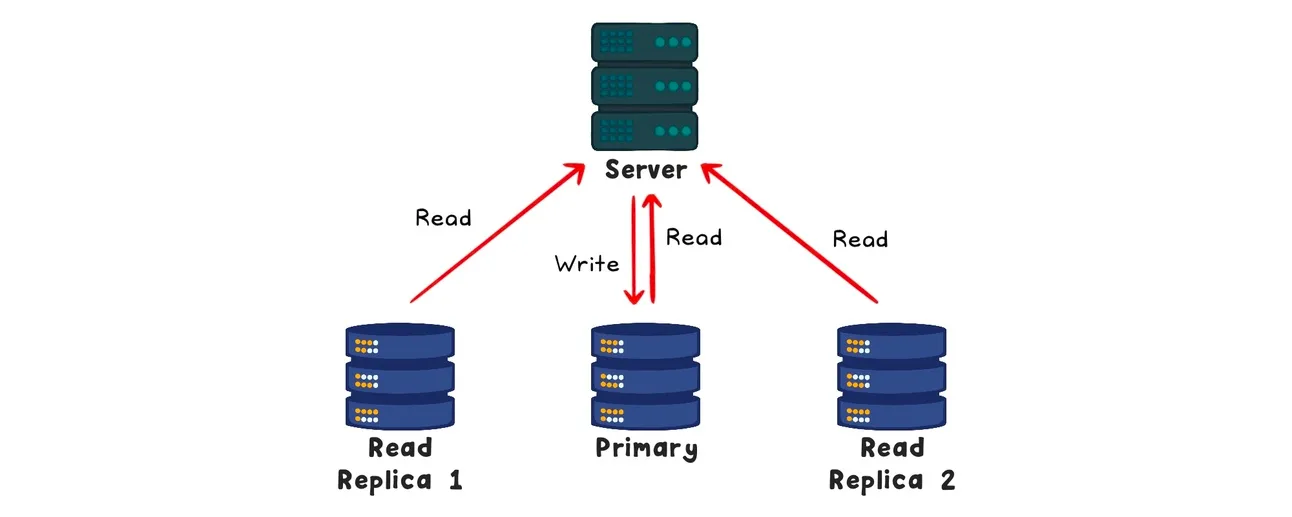
如果在缓存常见查询、创建高效索引和处理会话存储之后,数据库仍然承受着过多的读取负载,复制可能是下一个最佳解决方案。
通过读取复制,一个主数据库处理写入操作,而几个副本(在不同的机器上)处理读取操作。这种设置提高了写入性能,分散了读取负载,并通过在不同地区放置副本来优化读取速度。然而,可能会存在数据不一致性,因为写入的数据传播到副本需要时间。对于实时更新,比如立即渲染个人资料,你可以从主数据库读取。尽管读取复制提供了强大的扩展优势,但它也有复杂性。在尝试更简单的解决方案后,再考虑这种方法。
数据库分片
大多数扩展方法都集中在管理数据库读取上。数据库分片旨在通过将主数据库分割成更快、更易管理的“分片”来解决读取和写入问题。
有两种分片技术可用:水平和垂直。水平分片将表分布在不同的机器上,这些机器具有相同的列但唯一的行。垂直分片将一个表分割成不同的表,分布在不同的机器上,每个表都有唯一的行和列。
分片提高了查询速度,并增强了系统对故障的抵抗力。在分片设置中,通常只有一个分片受到影响,而不是整个系统。
尽管分片提供了显著的好处,但它增加了很多复杂性,这意味着高昂的设置和维护成本。在其他扩展解决方案都已耗尽后,应考虑分片。
数据管理系统在不断发展和增长,开辟了其他扩展数据库的技术。尽管有许多替代方案,但上述五种技术将继续是适用于现在和未来大多数用例的强大技术。
Citations: [1] https://www.mongodb.com/basics/scaling [2] https://www.freecodecamp.org/news/understanding-database-scaling-patterns/ [3] https://www.codecademy.com/article/database-scaling-strategies [4] https://thenewstack.io/techniques-for-scaling-applications-with-a-database/ [5] https://realscale.cloud66.com/database-server-scaling-strategies/
Share
If this article helped you, please share it with others!
Some content may be outdated